Extracting potential Travel time information from raw GPS data and Evaluating the Performance of Public transit – a case study in Kandy, Sri Lanka
Principal Investigator: Shiveswarran Ratneswaran
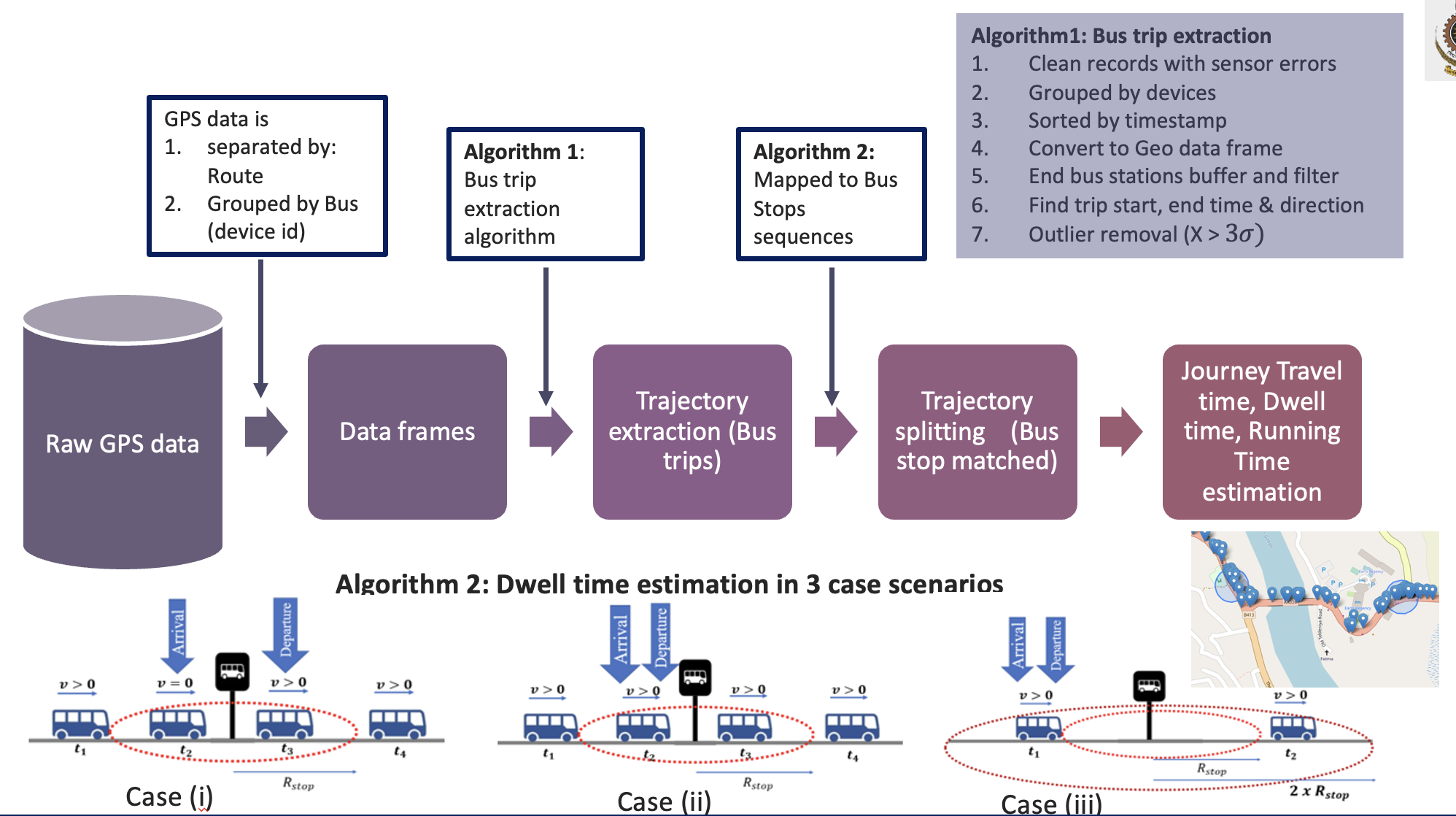
The widespread use of location-enabled devices on public transportation vehicles produces a huge amount of geospatial data. The primary objective of this research study is to build a solution framework that can process a large amount of geospatial data obtained from GPS (Global Positioning System) receivers fixed on different buses on different routes, preprocess, clean, and transform that data for analysis. There are various challenges associated with the processing of GPS data, like discontinuities, non-uniformities, poor network coverage, and human errors. This study proposes two novel, simple algorithms to extract bus trip and bus stop sequences, from the crude raw data, incorporating those challenges. Moreover, the dwell times at the bus stops are estimated solely using this GPS data in three different possible scenarios in the data filtering process. When considering the previous related studies in this area, the proposed approaches are applied to GPS data obtained at a medium sample rate (for example, 15 seconds) for heterogeneous traffic conditions, and also with a unique dwell time estimation process. In addition, statistical methods are implemented to analyze a variety of novel public transit-system performance metrics, such as (i) excess journey time (EJT); (ii) excess dwelling time (EDT); (ii) excess running time (ERT); and (iv) segment idle time ratio (SITR), at different time horizons, where these metrics are developed in the absence of schedule data. These metrics facilitate the transport authorities in real-time bus monitoring, evaluating their performance, and identifying inappropriate driving behaviours. A detailed explanation is provided through a case study of two main routes in the Kandy district of Sri Lanka.
Link for publication: https://doi.org/10.1109/ICCT56969.2023.10075789
Link for open-sourcce package: https://pypi.org/project/gps2gtfs/0.1.0/
Keywords—Travel time, GPS data, public transit, performance metrics
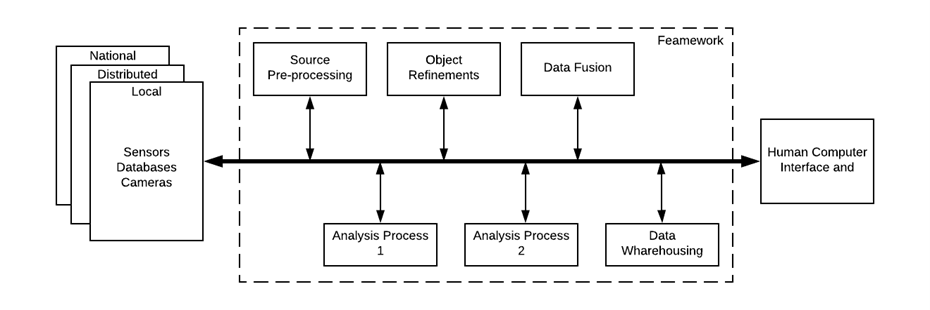
Data Fusion Framework for Facilitating Data Usage Across Multiple Applications
Principal Investigator: Buddhi Ayesha
To support the analytics of our Data-Driven Transportation Analytics system, we have developed a Data Fusion Framework for facilitating data usage across multiple applications. This system is categorized into four major sections, with the first being data fusion. The data fusion module focuses on storing and combining data from various sources such as traffic data, parking data, goods transfer data, land use map data, OSRM map data, CDR data, GPS data, HVS data, satellite data, bus ticketing data, accident data and video data. Data sources are added to the Data Lake or Data warehouse. Apache Spark is used as an analytics engine. Data integration and warehouse management were done using standards, and APIs were provided for third-party access to the data. The data was then used to detect traffic congestion and applied as an approach to reduce congestion and facilitate ride-sharing among passengers in an effective manner. This data was also used to segment travelers based on their demographics, interests, and travel patterns. We have successfully developed the data fusion module, which is an integral part of the proposed infrastructure. The data collected is stored in a data warehouse, and the data fusion module uses this data to combine and create/optimize features, providing these fused data for further analysis.
Objectives
- Identify required and appropriate data sources effectively.
- Pre-process data into an efficient standard format.
- Develop a data warehouse to store data coming from different sources.
- Implement a valuable information obtaining mechanism.
- Implement the data visualization platform.
Keywords: Transportation Data warehouse, Data science, Data Fusion, Transportation Analytics System
Vehicle detection and path identification leveraging machine learning and electromagnetic emissions
Principal Invesitgator: Anjana Wijesinghe
Traffic count surveys have been carried out since the introduction of traffic management, contributing to reducing traffic congestion. Traditionally conducted by manpower, traffic density and complexity of intersections dramatically increase required manpower while producing highly inaccurate results without professional training. Thus, automation of traffic surveys is essential; as video analysis face criticism due to privacy concerns, alternate methods are necessary. Previous research show vehicles emit magnetic fields and radio frequencies (RF) as the engine runs. Vehicles can be recognized using these emissions in combination with machine learning (ML). This research investigates the use of vehicle emissions to uniquely tag vehicles moving through an intersection using ML. In parallel to sensor data collection, video footage of the intersections will be captured as ground truth and for validation. The proposed unique vehicle tagging system considers the characteristics of the emissions in defining a unique tag. The vehicle occupancy of the intersection can be illustrated using the unique tag generated. Successful completion of this project enables vehicle count surveys to be carried out with minimal manpower and low-cost low-powered devices.
Objectives:
Develop an ML-based system to automate traffic count surveys.
- Fabricate device to record RF and magnetic emissions.
- Detect vehicles moving through the given area.
- Generate a unique vehicle identifier.
- Derive the entrance and exit paths that are taken.
- Generate the vehicle occupancy for the intersection.
Keywords: Electromagnetic data, Vehicle detection, Path identification, Machine learning, Path prediction
Identifying the travel patterns of on-demand taxi trips through inferred trip purposes
Principal Investigator: Dineth Dhananjaya
Transport demand is a derived demand. End-to-end transport or tour can be broken into a series of trips. Each trip has its purpose of being fulfilled during a tour. While some passengers use their private vehicles on all the trips, others usually rely on different available modes. Among those modes, demand-responsive services like taxis play a dominant role in urban communities, and with the advancement of smart devices, their demand has increased drastically. Almost all these taxies are deployed with a GPS device that accurate process data relates to different travel attributes except the purpose of a trip. However, as this is a critical attribute with appealing advantages in a vast area of applications, researchers have made efforts to create methods to mine the trip purpose from GPS data. The enrichment of the data of on-demand taxi trips of a service provider with the trip purposes provides the ability to identify and predict the travel patterns of its passengers. This is highly useful to pre-orient the taxis where the demand could attract more passengers. Furthermore, it can also be improved towards bringing features such as customer recommendation services for the passengers to intervene at their destinations. As a social benefit, identified travel patterns can be used as a specific input to implement better traffic management approaches based on the predicted travel demand on arterials. Hence, this project focuses on developing a model to infer the trip purposes of on-demand taxi trips and identify the travel patterns of on-demand taxi trips concerning the temporal regularities, spatial dynamics, trip directions, and trip lengths.
Keywords: GPS data, trip purpose inference, travel patterns, on-demand taxis, travel behaviour
Using Traffic Simulation Models to better understand and manage Urban Traffic
Principal Investigator: Thenuwan Jaysinghe
Modeling transportation systems using computer software helps to better plan and operate transportations systems. In fact, the use of transportation models is essential for sensible decision- making as planners can analyze and evaluate the impacts to the network from a proposed solution before implementing them in the real world. Developing accurate transport models require a large amount of time as i) it requires multiple data inputs in the model creation process, ii) proper calibration is required to match the ground truth. This research aims to introduce automated methods for model creation and calibration so that the time required for model development can be minimized while maintaining a higher level of accuracy in the model. Such models will be used to evaluate how different interventions for public transport (bus operations) can impact improving the traffic conditions in a given corridor.
Keywords: Transport modeling, model calibration, public transport priority
Investigating the Impact of Lane Violations on the Performance of a Curb side With-Flow Bus Priority Lanes: A Simulation Based Approach
Principal Investigator: Gayasha Samarakoon
Priority treatment for buses is inevitable in cities with severe traffic congestion where buses hold the highest mode share and infrastructure augmentations are costly. The success or failure of a Bus Priority Lane (BPL) depends on the degree of enforcement. This is especially important in curb side BPLs, where curb side activity such as loading/unloading of passengers as well as goods is frequent. However, enforcing BPLs to a level of no violations is impossible. The violations must be maintained at a level where they have a minimal impact on the performance of the BPL. Therefore, investigating the impact of violations on BPLs depending on type of violation (driving or parking) as well as frequency of violations is important. The current research attempts to investigate the impact of violations on the performance of curb side BPLs using a microsimulation model built using an open-source software.
Keywords: Bus Priority Lane, BPL Violations, BPL Performance, Microsimulation
Estimating National Level Fuel Economy and Emissions using Emerging Big Data Sources for Sustainable Environment
Principal Investigator: Mavin De Silva
Transport is one of the sectors targeted to reduce Green House Gas (GHG) emissions and where adaptation measures are needed to reduce the global vulnerability to climatic changes. Currently, the GHG emissions from the transport sector are about 30% in developed countries, making about 23% of the total man-made GHG emissions worldwide. Growth in GHG emissions has continued in spite of more efficient vehicles and policies being adopted last few decades. Without aggressive and sustained mitigation policies being implemented, transport emissions could increase at a faster rate than emissions from the other energy end-use sectors. New vehicle GHG and fuel economy standard regulations are designed to incentivize manufacturers to offer the most technologically efficient vehicles in the market. Policies and programs designed to incentivize the demand of more efficient vehicles are important complementary measures to take into consideration and action. Emerging big data sources namely Vehicle Emission Testing (VET) centers, Department of Motor Traffic (DMT), Sri Lanka Customs present new opportunities to review and analyze impacts and relationships of past and current fuel economy policies, and develop nationally appropriate policies to further promote more efficient vehicles including Electric Vehicles (EVs). These data sources include static data such as VET data, new vehicle registrations data, import tariff data and etc. Estimating fuel economy and emission values along with simulating the impacts of fuel economy policy changes for different scenarios would enable reaching the indigenous fuel economy targets. Therefore, these big data inputs are being used to build a novel methodology for fuel economy modeling of new vehicle registrations.
Keywords: Big Data, Fuel Economy, Emission Modelling, Fiscal Policies
SigmaLaw: Legal Information Extraction
Principal Investigator: Gathika Ratnayaka
Lawyers and paralegals spend a lot of time searching for the information they need from legal documents for a given task or a court case. Such legal documents - presenting the statutes (laws) and court cases - are generally available online. We currently have specific focus on Case Law which can be described as a part of common law, consisting of judgments given by higher (appellate) courts in interpreting the statutes applicable in cases brought before them. In order to find useful information from documents related to a given legal scenario, lawyers and other legal officials have to spend a significant amount of effort and time. Keyword-based search over these documents, as carried out by web search engines, is not sufficient here because a more sophisticated understanding of the contents is needed. Absence of a system or a research methodology that can represent legal information in an intuitive and well-structured manner is a major challenge when it comes to facilitating legal officials via an autonomous system. Thus, our system and methodologies are to be of assistance to lawyers and other legal officials by reducing the time and effort a lawyer has to put into find court cases and arguments related to a new legal scenario. Within this project, we have already initialized the development of research methodologies and resources which are required to organize the information available in court case transcripts (legal opinion text) in a systematic manner. Domain specific neural word embedding models, a legal ontology , legal information retrieval systems, system to identify relationships existing between sentences in legal opinion texts and a domain specific sentiment annotator are some of the tools and methodologies which have already been developed. The objective of this project is to develop an information extraction system for law which helps lawyers and paralegals in their work. Identifying major parties related to a court case, extracting arguments brought forward by each party, detecting counter arguments for a particular argument and identifying the party which is supported by a particular argument (or a legal opinion) can be considered as some of the future directions of the project.
Spatio-Temporal Analysis of Dengue Epidemic in Sri Lanka using Mobile Network Big Data based Mobility Models
Principal Investigator: Gayan Kavirathne
Dengue is the most rapidly spreading mosquito-borne virus in the world. In Sri Lanka, there have been 51591 dengue cases for the year 2018. Since there is no vaccine or therapeutic protocol against dengue, outbreak preparedness is an important technical and operational element as suggested by WHO. Such a preparedness plan would help to deal with the inflow of patients, medical supplies and facilities, political issues, and vector control. Yet, existing epidemic forecasting models do not provide an accurate usable solution. Human mobility is considered a major factor for epidemiology and it’s crucial for successful epidemic forecasting. Due to the absence of proper data sources in developing countries like Sri Lanka, CDR (Call Details Records) data is a very useful source since the vast majority of people have access to mobile communication devices and the user mobility can be modeled using CDR data. Dengue epidemic forecasting requires multiple data sources due to the fact that the spread of the disease depends on multiple factors. Human Mobility is one such vital factor in the forecast of spread of the disease. There are multiple human mobility models such as the gravity, exploration and Preferential Return, etc that are used in the literature. Existing risk-based mobility models compute risk scores for a given location based on domain intuition. Increased precision on the risk score might lead to improved forecasts for the epidemic model. A data-driven approach, to find precise values for the risk score using sensitivity analysis, formulas and/or penalty based methods based on past data can be explored.
Objectives
Developing or improving existing human mobility models using CDR data to derive a vector in addition to other vectors, in order to successfully predict spatio-temporal visibility of dengue outbreaks.
Deriving a pre-processing computational framework for CDR data to be used for risk-based mobility models.
Identification of the most suitable data-driven risk-based mobility model for Dengue forecasting
Developing a platform to utilize human mobility on the state of the art dengue forecasting technologies for automating data flows, analyzing, visualizing and alerting.
Keywords: Mobile Networks Big Data, Epidemic modeling
Developing a Retrieval-based Tamil Language Chatbot for Closed Domain
Principal Investigator: Kumaran Kugathasan
A chatbot is a conversational system which interacts with human users via natural language. Based on the approach used for developing, the chatbot system can be categorised as retrieval systems and generative systems. Current research in low-resourced language chatbot systems focuses mainly on machine learning based retrieval models since generative approaches will require many language-related resources, tools and experts which is normally not available for low-resourced languages. The retrieval-based system picks a response from a fixed set of responses based on the input and context using a rule-based approach or by using machine learning classifiers. High inflexion and free word order pose key challenges to Tamil language chatbots. A practical challenge in using chatbots is that the user may not express entirely in Tamil but mixed with English. Currently available Tamil chatbots dominantly suffer from these challenges even for a closed domain. Hence, a suitable approach to develop a Tamil language chatbot for the closed domain need to be explored.
Travel Behaviour Analytics using GPS Probe Data for Public Transportation Services.
Principal Investigator: Sudeepa Nadeeshan
Global Navigation Satellite System (GNSS) is a technology that provides positioning, navigation, and timing services on a global or regional basis. There are several GNSS systems like GPS, GLONASS, Galileo, Beidou etc. GPS is a network consists of a series of satellites that are orbiting the earth at an altitude of 19,300 km, broadcasting signals to receivers on the ground. A receiver can determine its location using data from at least four satellites. GPS tracking data over a specific time period can be used to analyse mobility behaviours in the selected context. Properly collected GPS data can be used to analyse driver behaviour, traffic and route information, to learn transport mode and to gain insights into public transport travel time variability. Public transport systems are put in place to provide a service to the citizens and the proper functioning of the public transport system is vital for a country. Monitoring of the service provided can be used to maintain and improve the Quality of Service. GPS data and other supplementary data obtained from vehicles used for public transport can be used for monitoring the service. The underlying process of analysing the mobility behaviour requires (1) a preprocessing pipeline which converts the data into transport-related indicators based on the sample size and the acquisition frequency, (2) a map matching to match the GPS data to digital map and (3) a data reduction subtask. Service quality monitoring can be done by visualizing the acquired data by conducting descriptive and diagnostic analytics and incsetain cases using machine learning techniques. The computational challenges that needs to be addressed to accomplish a usable visualization will be addressed in this project.
Keywords: Public Transportation, Intelligent Transport Systems(ITS), GPS Data Mining, Travel Behaviour Analytics
On Demand High Capacity Ride Sharing for Mobility on Demand (MoD) Systems
Mobility-on-demand (MoD) systems are emerging as a novel mode for urban mobility which provide users with a reliable mode of transportation that is catered to the individual needs. Ride sharing services provided by these mobility on demand systems provide not only a very personalized mobility experience but also present immense potential for positive societal impacts with reference to pollution, energy consumption, congestion, and etc. Ride sharing services primarily concern with picking up spatiotemporally distributed mobility demand and delivering it within a pre-specified time window subjected to different constraints. Large scale ride sharing in more sophisticated spatiotemporally distributed mobility demand distributions, require well designed mathematical models and algorithms in order to match riders and vehicle fleets in real time. In this research, the motive is to design and develop a dynamic model for ride sharing which is reactive anytime optimal and can perform dynamic vehicle assignment in an effective and efficient manner while being able to scale well with both sparse and dense spatio-temporal demand distributions.
Keywords : Ride sharing, Human Mobility, Vehicle Routing, Smart Cities, Intelligent Transport Systems, Mobility on demand.
Customer profiling to improve service and management of mobility on demand systems.
In the modern era of big data, many systems which provide various services thrive to gather data related to the customer-system interaction. Mobility on demand systems can be recognized as a similar type of a system, which gathers a massive amount of data related to customers mobility on a daily basis. Identifying and characterizing different customer profiles within the customer base by analyzing this data related to the customer mobility is quite important for the strategic decision-making process. Hence, this project explores algorithms and techniques that are suitable to model customer related data of “mobility on demand” systems in order to profile customers to support predictive management and service enhancement of the system.
Key-words : Data-Mining, Mobility on demand systems, Customer profiling, Customer segmentation
Affect level opinion mining of Twitter Streams
Twitter is a social media platform which is used by millions of users to express their opinions freely. There are about 120,000 active twitter users in sri lanka. Because of the rapidly increasing number of tweets, mining people’s expressed opinions in tweets on interesting topics has attracted more and more attention. Mining of these opinions manually is an impossible task, thus we have to employ automated methods to summarize the opinions. Opinion of a tweet can be summarized at the level of sentiment polarity or more finer level of expressed emotion. In this research our goal is to develop an emotion analysis algorithm which can accurately recognize emotions in a given tweet and provide an approach to identify the emotion intensity for group of tweets related to a single topic.
Keywords: data-mining, opinion-mining, affect, social-media, twitter
Developing a Trip Distribution model for Identified Mobility Groups using Big Data
Principal Investigator: Buddhi Ayesha
Transport infrastructure is a crucial component of the economy and a standard tool used for development. The satisfactory outcome of transport depends on the effectiveness and efficiency of infrastructure planning, which involves expensive and time-consuming human intervention in current conventional approaches. Ubiquitous mobile usage and the massive data it generates present new opportunities to assess the demand for this infrastructure, diagnose problems, and plan for the future. These data sources include passively collected data, such as mobile phone network data (Call Details Records (CDR) and Visitor Location Registry (VLR) data), smartphone GPS data, etc. Further, these newer data sources have the ability to complement conventional data, as proven by previous studies. However, before these benefits can be realized, methods must be found to integrate such new data sources with existing transportation planning frameworks, such as widely used travel demand models like the four-step model and direct demand models. Therefore, the current research study aims to reformulate a comprehensive transport demand model based on new big-data inputs.
Keywords: Data mining, Big Data, Machine Learning, CDRs
Forecasting Agricultural Crop Yield using Remote Sensing Data & Machine Learning
In recent years, sustainability of the agriculture sector has been threatened due to devastating environmental hazards and severe climate conditions that has occurred all over Sri Lanka. Gathering data of environmental catastrophes and important environmental factors such as temperature, soil moisture & atmospheric humidity etc., estimating effects of them on agriculture are necessarily involved in highly error-prone & time consuming human interventions in current traditional approaches. Policies and decisions taken by authorities of the government and other stakeholders are highly susceptible to flaws of current approaches. The tendency to employ data science and remote sensing techniques together in the field of agriculture is limited in developing countries due to scarcity of remote sensing resources till recent years. The objective of this research is to explore the untouched synergy of the remote sensing and machine learning methodologies in order to enable a data driven policy & decision making culture in agriculture sector.
Keywords: Remote Sensing, Big Data, Machine Learning, Agriculture, Data Driven Decision Making